Zhruba 681 miliónov tranzistorov v 90nm čipe: G80 (NV50) je tretia veľká architektonická novinka od uvedenia GeForce série. NV 10 (GeForce 256) priniesol register combiner, NV30 (GeForce FX) priniesol "CineFX". Sú to nové prístupy k danej problematike ako je aj G80...
Úvod, nezávislé takt domény v G80, shader core:
Možno povedať, že sa špecializované 3D čipy vyvinuli preto, lebo sa chceli použiť textúry. Rendering bez textúr by bol pri prijateľnej rýchlosti možný aj na procesoroch. Keď však chceme vidieť textúry a podľa možnosti aj filtrované, preťažíme podmienečne každé CPU. Tak boli vyvinuté grafické čipy s 3D funkciami a filtráciou textúr.
Pri NV10 sa však myslelo už ďalej. Čítať textúry z pamäte, filtrovať a nanášať na trojuholníky je pekné, ale prečo nedať vývojárom väčšiu kontrolu nad tým ako sú tieto údaje spoločne s interpolovanými vertex údajmi prepočítavané ? Register combiner ponúkol v tom čase ohromujúcu flexibilitu a výpočtový výkon práve pre tieto úlohy. S loopback a jedným prednastaveným texture shaderom sa to od GeForce 3 nazývalo dokonca "pixelshader". NV30 priniesol omnoho viac presnosti a flexibility pre pixelshading. Kvôli tomu bola vyvinutá CineFX architektúra. Pre GeForce 6 bolo CineFX od základov prerobené a vylepšené. Teraz s NV50 (G80) prichádza k nám znovu, naozaj nová architektúra. Spolu s G80 založila nVidia základový kameň pre svoje budúce čipy.
Nezávislé takt domény v G80:
| Odborný výraz: | Funkcia: |
| Interpolátor | vypočítava určité input hodnoty pre pixelshader |
| Shader-ALU | vykonáva shader výpočet |
| TMU (Texture Mapping Unit) | poskytuje filtrované hodnoty textúr Shader-ALU |
| ROP (Raster Operation) | vykonáva konečné práce na pixeloch |
Unified Shader hore alebo dole, potrebné jednotky ostali a môžu byť do veľkej miery využívané pixel, vertex alebo geometry shaderom. ALUs, TMUs a ROPs sú pri G80 do určitej miery odpojené. G80 má dve takt domény. Shader-ALUs (ku ktorým patria aj interpolátory) bežia u GeForce 8800GTX na frekvencii 1350MHz, zvyšok čipu (TMUs a ROPs) na 575MHz. Tieto frekvencie sú nezávisle od seba nastaviteľné. Zatiaľ čo je pomer jednotiek ALUs/TMUs u G80 pevný, dá sa ALU/TMU výkon meniť cez takt.
V priepustnosti pamäte ide nVidia tiež novými cestami. GeForce 8800GTX má 384-bit DDR zbernicu a 768 MiB RAM. GeForce 8800GTS má 320-bit DDR zbernicu a 640 MiB RAM. Skalárnosť architektúry rozšíriť aj pre zbernicu, priepustnosť je niečo nové. Pokiaľ sa v článku píše o G80 myslí sa na GeForce 8800GTX a pri G71 na GeForce 7900GTX.
Shader core:
G80 poskytuje v prípade GeForce 8800GTX osem aktívnych Vec-16 ALUs, pričom môže ALU vykonať za takt MUL, ADD a ešte jednu MUL (try floating point operation - 3 Flops na jeden skalárny kanál). MUL znamená multiplication, ADD addition. Väčšina shader kódu je naďalej vypočítavaný pomocou MUL a ADD. ALUs majú frekvenciu 1350MHz, čo dá teoretický aritmetický výkon 518 GFLOPs/s. (8 x 16 x 3 FLOPs/s x 1, 350 GHz = 512 GFLOPs/s) nVidia však ešte stále má čo robiť so schelduler-om, nakoľko je druhá MUL jednotka doteraz nevyužívaná – aspoň tak to vyzerá.
Krátke pripomenutie ako to vyzerá u NV4 a G70:
Tu to napríklad vyzerá tak, že pri prístupu k textúre je prvá Shader-ALU (pri NV40 MUL, pri G70 MAD) blokovaná. Pri CineFX máme "priebehovú pipe". Všetko čo ide do TMU jednotky, ktorá je medzi Shader-ALU 1 a 2, musí ísť najprv cez Shader-ALU 1. Táto prevezme so svojou MUL jednotkou k tomu ešte časť korektúry perspektív. Aj pri G80 by korektúra perspektívy nemala byť úloha interpolátora, ale čiastočne Shader-ALU. To však nevysvetluje, prečo je dosiaľ len jedna MUL jednotka za takt využitá. Pomôže nám to snáď objasniť čas.
Predchádzajúce architektúry (u ATi aj nVidie) využívali RGBA quadpipelines. Jeden quad sa skladá z 2x2 pixelov. Jeden pixel má štyri komponenty (RGBA). Preto musí byť ALU jednej quadpipe 16x (krát) poddelená (4 pixely á 4 komponenty = 16 operácii). V každej quadpipe sa tak za takt obvykle vypočítajú 4 komponenty zo štyroch pixelov. G80 má bloky so štyrmi skalárnymi quadpipes. Za takt sa tak vypočíta 16 komponentov zo 16 pixelov (4 quads). V konečnom dôsledku sa tak výkon rovná: pre jeden quad, čiže 4 pixely, vykonať Vec3 + Vec1 operáciu trvá väčšinou jeden takt.U G80 trvá vykonať Vec3 + Vec1 operáciu štyri takty, za ten čas sa však dokončia aj štyri quady – 16 pixelov. Okrem toho existuje veľa prípadov, kde pracuje G80 efektívnejšie. K ním sa vrátime neskôr.

SLI zapojenie dvoch G80 ponúka aritmetický výkon jeden Teraflop za sekundu; pri takom výkone vyzerá aj Cell procesor ako slabý. Grafické čipy sa ešte stále vyvíjajú rýchlejšie ako procesory.
| Teoretický aritmetický výkon: | |||
| G71 Pixelshader | 125 GFlop/s ADD | 125 GFlop/s MUL | spolu 250 GFlop/s |
| G71 Vertex Shader | 28 GFlop/s ADD | 28 GFlop/s MUL | spolu 56 GFlop/s |
| G80 Unified Shader | 173 GFlop/s ADD | 346 GFlop/s MUL | spolu 518 GFlop/s |
Ako ukazuje tabuľka, ponúka Unified Shader G80 väčší teoretický aritmetický výkon ako Pixel a Vertexshader G71 dokopy. Vďaka efektivite G80 je využiteľný výkon ešte o kus vyšší ako u G71. Tieto čísla sú len teoretické maximá. Vyvodiť z rozdielu medzi nimi, výkonnostný rozdiel medzi G80 a G71 by bol nezmysel. Okrem toho vychádzam z predpokladu, že Shader-ALU využíva dve MUL operácie za takt. Vyzerá to tak, že v praxi tomu tak nie je.Ešte raz: Nepoužívať prosím tieto čísla pre porovnanie výkon medzi G80 a G71, nakoľko majú v praxi aj iné veci vplyv na celkový výkon, ktoré ostali teraz nezapočítané.
Nové TMUs, nové ROPs:
Vysoký výkon shader-core by bol málo platný, keby nemal čip aj dostatočný textúrovací výkon. G80 by mal podľa obvyklého spôsobu počítania 32 TMUs (24 pri GTS). Pričom každá TMU dokáže za takt počítať dva trilineárne sample. Tieto dva sample však musia pochádzať z tej istej textúre. Takto sa dá trilineárne a anizotropné filtrovanie urýchliť. Trilineárne anizotropné filtrovanie by sa dalo ešte dodatočne urýchliť. Či nVidia túto (a úplne legálnu) optimalizáciu použije, aby ušetrila pri trilineárnom anizotropnom filtrovaní 25% samplov sa musí ešte zmerať.
Vychádzať z predpokladu, že G80 má vlastne "64 TMUs" nie je správne, nakoľko je za takt možné vytvoriť maximálne 32 filtrovaných texel-ov. Tieto 32 TMUs sú však lepšie ako 32 trilineárnych TMUs, pretože je urýchľované aj AF. NV10 (GeForce 256) mohla pri podobnom systéme urýchľovať len trilineárne filtrovanie. S urýchlením trilineárneho filtrovania sa samozrejme urýchli trilineárne AF. GeForce4 Ti nemohla ako jediná výnimka s dvoma bilineárnimy TMUs na pixelpipe urýchľovať bilineárne AF, čo GeForce 3 a aj GeForce FX umožňovala.
Teraz chcem objasniť, či poskytovaná priepustnosť pamäte vôbec stačí na vyťaženie TMUs. Pri 32 Bit textúrach a predpoklade, že pri každom bilineárnom sample musí byť v priemere čítaný 1 texel (a zbytok prichádza z cache), bolo by len pre textúry potrebných 147.2 GB/s. Pri nekomprimovaných textúrach tak nie je dostatočná priepustnosť. (147.2 GB/s by bolo potrebných, ale len 86.4 GB/s je dostupných) – avšak output výkon je stále neprekonaný. Pri všetkých DXT formátoch (s maximálne 8 Bit na texel) je ponúkaná priepustnosť dostatočná.
TMUs sú do určitej miery odpojené. Každá Vec 16 ALU disponuje nad "štyrmi" TMUs a môže len tieto pre svoje výpočty použiť. Tieto štyri TMUs sú v skutočnosti jedna TMU so štvornásobným poddelenými jednotkami. Pričom je každá zo štyroch poddelených filter jednotiek ešte dvojite vyložená. Pri porovnaní texel výkonu s aritmetickým výkonom musíme samozrejme zohľadniť aj rozdiel frekvencií.
Threading mechanizmus sa stará o to, aby pri filtrovaní textúr bola ALU zásobovaná a vyťažená inými pixelami. Pokiaľ je potrebné, dokážu ALUs aj Vertex výpočty vykonávať a TMUs filtrovať textúry pre Pixelshader. Výpočtovým jednotkám je úplne jedno, odkiaľ k ním prídu dáta, nakoľko Unified Shader konzept vedie shadre cez tie isté ALUs. Dostať potrebné dáta v správnom poradí z ALU vyžaduje určité prepínače, ktorých komplexita je v porovnaní s počtom tranzistorom pre výpočtové jednotky často podceňovaná. S G80 threadingom sa ale nedá dosiahnuť maximálna efektivita. Preto neplatí: počet potrebných taktov = maximum z TMU a ALU taktov. Toto by mohlo byť v ojedinelých prípadoch dosiahnuté, ale nie vždy. V porovnaní s G70 je ALU oveľa zriedkavejšie blokovaná textúrovaním. Pomocou threadingu sú TMUs ale aj ALUs oveľa viac vyťažené, výkon za takt je preto oveľa väčší ako pri G70.
TMUs v G80 teraz vedia aj FP-32 filtrovanie textúr. To nie je žiadne prekvapenie, nakoľko môže byť Unified Shader použitý aj ako Vertexshader a vo Vertex úrovni sa vždy pracuje s FP32 – čiže používať aj FP-32 textúry. (NV40 a G70 môžu vo Vertexshadery pristupovať na textúry len nefiltrovane) FP32 filtrovanie textúr beží len štvrtinovou rýchlosťou a FP16 filtrovanie textúr len polovičnou rýchlosťou voči normálnemu RGBA8888 filtrovaniu textúr. FP32 filtrovanie textúr možno samozrejme využiť aj na prácu s pixelami.
Nie je mi dosiaľ jasné ako je filtrovanie FP16 a FP32 hodnôt interne realizované. Avšak to nie je pre prax podstatné. Podstatné je ale, že aj pri FP16 textúrach je možné za takt filtrovať 32 texel-ov – v praxi limituje priepustnosť. Napriek tomu môžu byť určité veci pri HDR Renderingu na G80 realizované veľmi efektívne. G71 a R580 majú pri zmysluplnom HDR Renderingu len čiastočnú podporu features. G80 dokáže pracovať s pohyblivou rádovou čiarkou, bez toho aby stratil multisampling schopnosť (G71) alebo filtrovanie textúr (R580)
| Teoretický texel výkon pri 32 Bit textúrach (RGBA8888) | ||
| G71: | G80: | |
| bilineárne Samples | 15,6 GT/s | 18,4 GT/s |
| trilineárne Samples | 7,8 GT/s | 18,4 GT/s |
| 2x AF bilineárne* | 7,8 GT/s | 18,4 GT/s |
| * pri zmenšených a rozmazaných textúrach | ||
Nielenže je základný textúrovací výkon vyšší, ale je trilineárne alebo 2x AF (čisto z hľadiska texelfillrate) zadarmo.Odpojenie pomáha aj tomu, aby sa TMUs a ALUs zriedkavejšie medzi sebou blokovali. Podľa môjho názoru je nastavenie ovládačov pri default neakceptovateľné, nakoľko neponúka od 2x AF trilineárne filtrovanie. Túto "optimalizáciu", ktorá zakáže plnú trilineárnu filtráciu musí používateľ manuále v ovládačoch vypnúť. Pri pohľade na extrémne dobrú TMU achitektúru G80 je tento krok nVidie úplne nepochopiteľný.
Nové ROPs:
V GeForce 8800GTX je šesť ROP blokov, päť v GeForce 8800GTS. (odpovedajúc počtu jednotlivých 64 Bit pamäťových pripojení) Na jeden blok pripadajú len štyri Alphablending jednotky, ale až 32 Z-test jednotiek. Pokiaľ je v hre aj farba dá sa využiť ešte 16 Z-test jednotiek. (táto "optimalizácia" so zdvojnásobením Z/Stencil testrate pre bezfarebný Stencil a Z-rendering existuje už od NV30)
G80 ROP sú podľa toho optimalizované pre 4x Multisampling. Na prvý pohľad nerozumne vysoký počet 192 Z-testov za takt – pokiaľ nie je v hre žiadna farba – prinesie svoje využite pri prednostnom Z-pass. Doteraz trval prednostný Z-pass v porovnaní s renderingom ešte tak dlho, že v konečnom farebnom renderingu ho ušetrená fillrate nemohla kompenzovať – predovšetkým preto, že Vertexshader musel byť dvakrát použitý .
Pri G80 je veľký predpoklad, že s touto technikou sa celová rýchlosť zvýši, aj preto, že sa druhý Vertexshader pass nemusí konať. (pomocou zapamätania výsledko prvého passu) 3D engine so stencil tieňmi potrebuje beztak jeden prednostný Z/stencil pass. Jednoducho povedané: Z vysokého Z/stencil výkonu profituje kažá aplikácia, optimalizovaný sofware ešte viac vďaka efektívnejšiemu využitiu Vetex a Z/stencil výkonu.
| Teoretický output výkon: | ||
| G71: | G80: | |
| RGBA-8888-Alphablending | 10,4 GP/s | 13,8 GP/s |
| Počet pixlov pri 2x MSAA | 10,4 GP/s | 13,8 GP/s |
| Počet pixlov pri 4x MSAA | 5,2 GP/s | 13,8 GP/s |
| Počet zixelov pri 2x MSAA | 10,4 GZ/s | 55,2 GZ/s |
| Počet zixelov pri 4x MSAA | 5,2 GZ/s | 27,6 GZ/s |
Žiaden menovaný čip nevie využiť svoj output výkon, nakoľko limituje priepustnosť. Prečo implementovala nVidia také množstvo ROP jednotiek ? ROP jednotky sú v porovnaní s TMUs a ALUs pomerne malé, preto sa ich oplatí zabudovať viacej, aby neboli drahé ALUs vybrzdené.
Ďalšie vylepšenia, v čom nám pomôže Direct3D10 ?, detaily jadra:
Aj triangel setup výkon bol zlepšený, aby bol hoden nového pixelshader výkonu. Early-Z menovaný mechanizmus má za úlohu predčasne rozoznať prekryté (a tak neviditeľné) pixely a ich ani nepustiť do "pipeline". Tento mechanizmus bol tiež vylepšený. Presné čísla však nie sú známe
Detailné informácie ku cache systému žiaľ nVidia nedala. Obrovitánske cache pamäte však G80 nemá určite – pamäte je len toľko, aby bol možný bezproblémový chod. Pomocou threading mechanizmu sa dá prístupová doba k pamätiam pomerne dobre skryť. To je dôvod prečo si môže G80 vystačiť aj s menšími pamäťami cache. G80 vo forme GeForce 8800GTX potrebuje svoju priepustnosť pamäte (86,4 GB/s) tiež. (G71 má len 51,2 GB/s a GeForce 8800GTS 64 GB/s)
Málo detailov prezradila nVidia aj o vnútorných mechanizmoch pre komprimáciu. Bolo by však chybné sa spoliahať len na "hrubý výkon". Spolu s Direct3D10 je podporovaných osem rendertargets s odlišnou farebnou hĺbkou, vďaka ktorým sa dajú zrkadlové efekty alebo aj HDR lightning scény ľahšie vypočítavať.
G80 podporuje konečne 32 Bit Framebuffer s (integer) 10-10-10-2 formatovaním vrátane Multisampling podporou ako aj 64 Bit Fremebuffer (floating point) 16-16-16-16 takisto s Multisamplingom. Posledne menovaný je "lacnejší" pre scény, ktoré sú renderované s HDR lightningom . Prvý by bol "lacnejší" pre zbavenie sa v normálnych hrách tzv. colorbandingu, ktorý sa pri normálne formatovanom 32 Bit framebuffery vyskytuje v určitých hrách.
Pokiaľ viem, nie je žiadna možnosť v ovládačoch pre vynútenie 10-10-10-2, keď si aplikácia vyžiada RGBX (čiže nepotrebuje aplha kanál vo framebuffery). Existovala by takáto možnosť, bola by pri hraní Quake III veľmy užitočná.Samozrejme nie je 10-10-10-2 v integer formáte (napriek sRGB kódovaní) použiteľný pre HDR. Preto podporuje G80 aj 9-9-9-5 formát, pričom tých 5 Bit nestojí pre alpha, ale pre spoločného exponenta RGB hodnôt. Takého zadelenie Bitov vie 32 Bit šírka "slova" lepšie využiť, ako podobný "RGBE" formát s 8 Bit na kanál.
Aby sa nemuseli pri textúrach použiť hneď 64 Bit textúry, bol zavedený 11-11-10 formát s pohyblivou rádovou čiarkou.Obidve zobrazenia poskytujú podľa definície len middle dynamic range. To, že Multisampling funguje aj pri 128 Bit famebuffery (32-32-32-32) je pekné, ale zatiaľ bez významu.
Viditeľne zlepšené pri G80 sú antialaising a anizotropné filtrovanie.
| Názov AA: | Modus: |
| 2x | 2x multisampling |
| 4x | 4x multisampling |
| 8x | 4x multisamping s rozšírením na 8x masku* |
| 8xQ | 8x multisampling |
| 16x | 4x multisamping s rozšírením na 16x masku* |
| 16xQ | 8x multisamping s rozšírením na 16x masku* |
* rozšírená maska má účinok len na polygonoch a nie na stancil tieňoch. Nakoľko je zapamätávaných viac hĺbkových informácii ako informácii o pokrytí môže dôjsť k nežiadúcim "kopčekom".
Všetky masky využívajú sparse grid, ktorý poskytuje optimálne vyhladzovanie pre subpixely. Podstatné je, že s "8xQ" je poskytovaný 8x sparse multisampling so všetkým čo k tomu patrí. Čiže aj TMSAA, TSSAA. Textúry s až 8192 x 8192 texelmi sú teraz vo všetkých texel formátoch použiteľné.
Aj rendertarget môže mať teraz až 8192 x 8192 pixelov, čo umožní nové antialaising módy s integrovaným oversamplingom.
Podstatné vylepšenia sa uskutočnili u anizotropného filtrovania.
G80 poskytuje neadaptívne anizotropné filtovanie. Naďalej však môže HW využívať adaptívne anizotropné filtrovanie, ktoré poznáme z NV40 a G70. Neadaptívne anizotropné filtrovanie poskytuje vždy najlepší trade off zo straty výkonu a získanej kvality obrazu. Preto neposkytuje ovládač momentálne žiaden adaptívny model anizotropného filtrovania – nVidia tak znemožňuje do určitej miery použiť rovnaké nastavenia kvality obrazu.
Samozrejme existuje nebezpečenstvo, že by nVidia znovu využila "optimalizačný potenciál" AF textúr a štandartne by bol viditeľný shimmering – ako teraz pri NV40 a G70.
Ako som už spomínal: štandartne nie je pri zapnutom AF poskytované trilineárne filtrovanie. To musí byť zapnuté až užívateľom. To čo ATi a nVidia už určitú dobu nazývajú trilineárnym filtrovaním nazývame mi "brilineárne" filtrovanie. Je však lepšie ako bilineárne, objektívne však nie je trilineárne. Len trilineárne filtrovanie vponúka plnú trilineárnu kvalitu. Prekryť ostré MIP pásy bilineárneho filtrovania nie je plná trilineárna kvalita.
Nakoľko má G80 neskutočný texel výkon, čudujem sa nad podobnými optimalizáciami.
Skonštatovať však treba, že G80 má hardwarové predpoklady, aby zobrazoval najlepšie anizotropné filtrovanie. Či budeme vidieť dlhodobo plnú kvalitu, ostáva otázne – v minulosti implementovala nVidia tajne vždy rôzne optimalizácie, ktoré spôsobovali zhoršovanie kvality obrazu. Ostáva dúfať, že nVidia nezhorší kvalitu filtrovania textúr, čo by bol vinikajúci dôvod pre kúpu mainstream karty založenej na G80 architektúre.
V prvom rade by som odporúčal čakať, akú kvalitu filtrovania textúr ponúkne nVidia v stovkových ForceWare ovládačoch.
Nasledovné obrázky ukazujú filtrovanie, bez aplikačných optimalizácii:
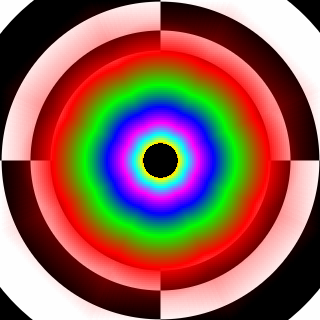
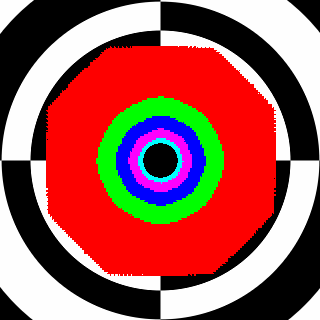
16x bilineárne: doposiaľ maximálny AF modus na GF3/4/FX (8x) S3 Delta/Gammachrome (16x) pri bilineárnom filtrovaní na MIP úrovni 1 skôr štvorec.Tento osem uholník je jednoznačne lepší.
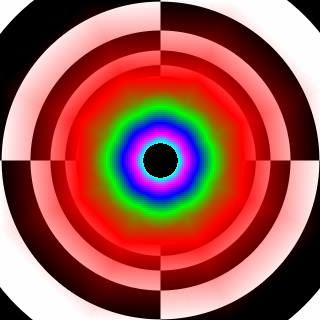
Plné trilineárne filtrovanie na G80 pri 16x AF – oveľa lepší výber MIP ako Radeon X1000 séria. Radeon filtruje v testery síce trilineárne, v hrách však skôr "brilineárne".
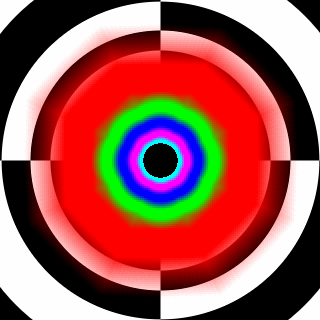
Štandartne je aktívne "brilineárne" filtrovanie. V praxi máme pri udanom trilineárnom 16x AF skoro bilineárne AF. Podľa mňa je to neakceptovateľná skutočnosť. (platí pre každého výrobcu a hlavne pre túto kartu – G80)
Týmto AF obrázkom však nemôže byť prikladaná väčšia váha – ukazujú jedine LOD výpočty, nezobrazia však možný shimmering pri podfiltrovaní.
V čom nám pomôže Direct3D10 ?
"Nemali by sme najprv úplne využiť Direct3D9 predtým než začneme využívať Direct3D10 ... ?" "Má G80 vôbec dostatočný výkon pre Direct3D10 efekty ... ?"
V DirectD10 stojí vývojárovi k dispozícii oveľa viac zdrojov (registre, konštanty, textúry atď...), čo zjednoduší programovanie rapídne. Preto by sme nemali najprv využiť Direct3D9, nakoľko sa komplexnejšie efekty dajú pod Direct3D10 rýchlejšie vypočítať. Už Shader Model 3 ponúka oveľa viac možností, ako voči Shader Modelu 2 znížiť zaťaženie procesora. Shader Model 4 pokračuje v tomto trende ďalej, aby bol procesor pri renderovaní ešte menej zaťažený.
Aj pomocou DirectD7 API by sa dali vytvoriť 3D hry, ktoré by G80 nedokázal plynule zobrazovať – preto je otázka, či je pre Direct3D10 "dostatočne výkonný G80" nezmyslená. Vždy to záleží na tom, čo chceme spraviť. 3D shootery, ktoré sa objavia ~ 2008 a budú pravdepodobne využívať Direct3D10, nebude G80 asi vedieť zobrazovať v najväčšej možnej kvalite plynule.
Avšak nemožno teraz prísť na nápad, že G80 obsahuje "Direct3D9" a "Direct3D10 jednotky". GPU má výpočtové jednotky, ktoré spracuvávajú dáta. Nie všetky sa však dajú využiť pre DirectD9 – to je ale nedostatok API a nie hardwaru.
DirectX zavádzal postupom času pevné kostry; rozširovanie tu nie je možné. Možno povedať, že Direct3D10 vyžehlí určité nedostatky predchodcu, bez zmien podstatných problémov. Direct3D je definícia, čo musí čip vedieť a ako bude kounikovať s ovládačom, Direct3D neprináša sám žiadne features. Features prináš čip.
Používateľom Windows XP zostane zatiaľ Direct3D10 nepoužiteľný. To nie je problém grafickej karty, ale softvérovej politiky Microsoftu. Kto tu bude komu škodiť sa uvidí. Nebolo by OpenGL konzorcium také ťažkopádne, mohli by sme túto alternatívnu API použiť pre "DirectD310 features". nVidia, ktorá sa ako obyčajne angažuje aj pri OpenGL, predstavila už nové extensions. (doteraz bolo možné pod OpenGL získať viac features z GeForce ako z odpovedajúcej DirectX generácie)
Vyzerá to tak, že AMD/ATi sa v tejto oblasti dotiahne (a PowerVR časom tieš). Ostávajú tak naďalej dobré dôvody pre nasadanie OpenGL API. Napriek sile Microsoftu – pri grafických kartách, koncových zariadeniach, ako aj pri novej Playstation 3 hrá OpenGL podstatnú úlohu. Nám užívateľom to otvorí cestu, získať novú flexibilitu aj na Windows XP, bez potreby emulovania Direct3D10.
Na tomto mieste neprinesiem naschvál ukážky, čo je všetko s Direct3D10 možné, nakoľko by prakticky všetky scény mohli byť renderované aj pomocou Direct3D9, len v menšej rýchlosti. Po druhé – technologické dema neodzrkadlujú skutočnosť, čo môžeme očakávať v hrách. A znovu – alebo ako často ešte ? – nám je Displacement Mapping sľubovaný. Tu však existuje množstvo principiálnych problémov, ktoré zťažujú nasadenie v real world hrách. Moja prosba na čitateľov – odvykať si od myslenia na efekty.
GPUs sú programovateľné, NV10 je len málo programovateľný, NV30 oveľa viac, NV50 (G80) by bol schopný pri vyhovujúcom Compilery nechať bežať jednoduchý C-code. G80 neumožňuje (odhliadnuc od nových Bit operácii v shader core, ktoré sa však ťažko emulujú) žiadne nové efekty.Umožňuje však flexibilnejšie programovanie a vyššiu výpočtovú rýchlosť ako všetky doposiaľ predstavené Consumer-GPUs ("spotrebné GPU"). To znamená, že umožňuje renderovať komplexnejšie efekty v reálnom čase.
Pokiaľ máme viaceré zdroje svetla, rozdielne hladké povrchy, ktoré musia byť zobrazené, možno rýchlo prísť aj k 11 (a viac) vplyvov, ktoré musia byť na jeden pixel prepočítavané. Preto potrebujeme nielen "hrubý výkon" ale aj hardware, ktorý vie teoretický výkon podľa možnosti čo najlepšie využiť. Na to sa teraz pozrieme v detaile.
Detaily jadra:
Skalár je jednoducho číslo, vektor je skupina z viacerých čísel. Preto možno chápať skalár aj ako vektor len s jedným komponentom. Jeden pixel je väčšinou znázornený ako 4D vektor ("Vec4"). Z toho tri komponenty na farbu v RGB systéme a jeden pre dodatočnú informáciu, nazývanú "alpha". Alpha je často využívaná pre odstupnovateľnú priehľadnosť. Nakoľko je pixel zobrazený ako vektor, dlhú dobu sa stavali Vektor ALUs. G80 však má "skalárne" ALUs, ale vždy pre 16 pixelov dokopy. Možno preto hovoriť aj o Vec 16 ALUs, ktoré pre 16 pixelov vypočítajú 16 vektor komponentov – 16 skalárov. G80 preto nemá 128 skalárnych pipelines. Takisto ani G70 nemá 24 pixelpipelines – je to šesť quadov. G80 má osem Vec16 quadov, ktoré sú však oveľa efektívnejšie a pracujú pri väčšej frekvencii.
Predpokladajme, že v shader kóde nasledujú tri skalárne operácie za sebou. Tieto tri operácie potrebujú u NV40 a G70 (ako aj na aktuálnych Radeon) dva takty, pretože môžu byť za takt maximálne dve rozdielne operácie "vedľa seba". Existujú aj iné obmedzenia, ktorými sa ale nebudeme zaoberať.Ako už povedané – quad pipe vypočíta za tak 4 pixely. G80 potrebuje pre tri skalárne operácie samozrejme 3 takty a nie 2 – ale vypočíta to pre štvornásobné množstvo pixelov (16 namiesto 4). "Efektívne" tak potrebuje G80 - 0.75 namiesto dvoch taktov.
DP operácie sú v G70 ešte priamo vykonané, u G80 musia byť rozdrobené na skalárne operácie. Takto sa dá DP však efektívnejšie vypočítať. Jednoducho povedané, lebo bude použitých menej ADD-ALUs. Zatiaľ čo G70 má okrem dvoch MULs aj dve ADDs, má G80 na svojích dvoch MULs len jednu ADD.
G80 architektúra tak vypočíta za takt na pixel menej ako G70, avšak viac pixelov súčastne. G80 má na quad a za takt polovičný ADD výkon ako G70. Má však vylepšenú efektivitu a pracuje pri oveľa väčšej pracovnej frekvencii, pri bez tak "širokej" architektúre.
Zaujímavé je tiež, že nová architektúra prináša aj zjednodušenia. Možnosť vykonávať v NV40 a G70 v jednej shader jednotke dve operácie za sebou, vyžaduje flexibilitu – čiže vedieť spracovať aj dlhé inštrukcie príkazov. (príkazy sú u GeForce kartách od CineFX, zapamätávané pamäťovým prístupom TMU do pipe pomocou VLIWs – Very Large Instruction Words.)
V G80 vykonávajú všetky ALUs tie isté inštrukcie a nemusia byť jednotlivo konfigurovateľné. To skracuje "dĺžku slova" VLIW – rozdelením na skaláry však stúpa počet potrebných VLIWs, na odpracovanie shadera. Nakoľko však registerfile zapamätáva len skaláry (vždy pre 16 pixelov naraz – kvôli šírke ALU), je tento efektívnejšie využívaný ako pri ostatných architektúrach. Pixelshadery G80 majú overhead pri ALUs, ktorý pri multitexturing shaderoch však nehrá rolu, nakoľko sú TMUs v tomto prípade beztak zaneprázdnené.
Špeciálne funkcie, branching performance, výpočet fyziky:
Ako som už povedal, shadre sa skladajú z veľkej časti z MUL a ADD operácii. Ale pre určité výpočty sú prídavné matematické funkcie veľmi užitočné. V princípe by sa dali realizovať aj cez textúr loop, ale odrazilo by sa to na výkone. Preto sú určité špeciálne operácie (SFUs) integrované priamo do ALU.
| Funkcia: | Účinok: |
| RCP | 1/x |
| RSQ | 1/x05 |
| EXP | 2x |
| LOG | log2 (x) |
| SIN | sin(x) |
| COS | cos(x) |
Tieto špeciálne funkcie zaberú pokiaľ vieme štyri takty na G80. Väčšinu SFUs existovalo už aj na G70 a je pre ne potrebný jeden takt. S tým však nie je spojené žiadne spomalenie – nakoľko SFUs vypočítavajú len jeden skalár. 24 "pixelpipelines" G71 dokážu pri pracovnej frekvencii 650MHz vypočítať za takt 24 SFUs. 128 "skalárnych pipelines" dokážu vypočítať pri frekvencii 1350MHz za takt 32 SFUs – G80 má tak zhruba 2.8 násobný SFU výkon v porovnaní s G71.
Branching performance:
Zatiaľ čo G70 mal batch veľkosť 220 quadov a jeden quad sa skladá zo štyroch pixelov, môže byť zmenený len 880 pixel batch PC (program countera). Takto je aj granularita pri Dynamic Branchingu "hrubozrnná" a to je už voči NV40 veľké zlepšenie. (pri NV40 si všetky quad pipes delil jeden jediný PC!)
G80 poskytuje granularitu veľkosti 32 pixelov. To je v porovnaní s R520 (16 pixelov) horšie, ale lepšie ako pri R580 (48 pixelov).Okrem toho odpadá pri skákavých príkazoch doterajší dvoj takt overhead z NV40/G70. (menovaný overhead neodpadol ešte pri žiadnej Radeon)
Výpočet fyziky:
Agea predstavila pomocou PhysX PPU kartu pre výpočet fyziky. Odvtedy sa ozývajú hlasy aj od iných firiem: "to vieme aj my". nVidia často poukazuje na to, že aj ich GPUs môžu byť použité na urýchľovanie fyziky. Tu však treba marketingové vyjadrenia posunúť bokom.
AMD mala pomocou "3DNow!" jednu v CPU integrovanú 2xSIMD výpočtovú jednotku, ktorú predával marketing ako urýchľovač grafiky. Intel išiel ešte ďalej a pomocou SIMD jednotky nazývanej ISSE, by malo byť (aspoň tak to bolo ponúkané) urýchľované surfovanie po internete. PPU od Agei, tak isto aj G80 GPU sa dajú využiť ako stream procesory. Čo je s tým myslené, je čipu jedno. On nevie či počíta grafiku alebo fyziku, proste spracuváva dáta.
G80 umožňuje vďaka integrovaným výpočtovým jednotkám v princípe, aby sme preňho kompilovali C-Code. So správnym slotom by sa G80 dal využiť ako paralelné CPU. Takýmto slotom je CUDA. Samozrejme neostane nVidia v tomto vývoji sama. AMD/ATi sa už teší aby sa ich GPUs využívali na "negrafické úlohy".
G80 by sa dal – hlavne vďaka Geometry shaderu – a trochou kreativity vývojárov využiť na urýchľovanie "physic" efektov (ako čistý fyzikálny efekt, bez relevantného vplyvu na hru), ktoré by boli integrované do enginu. Niektoré jednoduché efekty sa dali urýchľovať aj pomocou Vertex shaderu 1.1 už na GeForce3.
Výrobcovia grafických kariet naschvál neuvádzajú konkrétne čísla. Nie je to, ale žiadne prekvapenie, nakoľko bude grafická karta ukrátená o výkon ktorý sa využije pre výpočet fyziky. Čo spravia vývojári s ponúkaným výkonom, sa dá len ťažko odhadnúť – hlavne aj preto, že kým sa dostanú hry s fyzikou do predaju bude G80 už história – pokiaľ k tomu vôbec príde.
Kupec G80 nemôže v žiadnom prípade dúfať, že v blízkej budúcnosti uvidí v hrách geniálne fyzikálne efekty. Predpokladám, že vývojári stavia v budúcnosti primárne na multicore CPUs ako urýchľovače fyziky. Čisto z teoretického hľadiska, je G80 vhodný pre "negrafické úlohy", preto aj pre urýchľovanie fyziky. G80 ponúka v tomto momente najlepšiu kombináciu z všestrannosti a rýchlosti – som si istý. To je tiež dôvod, prečo sa vedci zaujímajú, ako využiť ohromný výkon za pár sto dolárov, hlavne pre "negrafické účely".
Záver, výhľad do budúcnosti:
AMD/ATi vyhlási Unified Shader rchitektúru a nVidia ju ponúkne pre koncového používateľa. Okrem G80 boli 8.11.2006 predstavené aj dva nové čipsety - nForce i680 generácie. Pre Intel aj AMD platformu. Kto má dostatočné financie dostane k dnešnému dňu od nVidie maximálny výkon a kvalitu obrazu. To, že G80 dosiahne nové výkonnostné hranice, sa dalo predpokladať. Prekvapivé sú však dva fakty – po prvé umožňuje G80 nekompromisnú kvalitu obrazu vďaka 8x sparse Multisampling Antialiasingu a takmer dokonalé 16x anizotropické filtrovanie v HighQuality móde. Pokiaľ samozrejme nVidia nepríde na nápad, pomocou optimalizácii, zhoršiť kvalitu filtrovania textúr.
V antialaisingu bola nVidia dlho druhá, teraz s G80 môžete s 8x sparse Multisampling ("8xQ") spolu s temporary anitalaisingom získať najlepšiu kvalitu vyhladzovania hrán v oblasti consumer grafických kariet. CSAA módy (8x, 16x, 16Q) sú oproti tomu len "hračky".
Ďalej je pôsobivé akým spôsobom zvýšila nVidia efektivitu čipu a efektivitu filtrovania textúr. Samozrejme, ani G80 nie je dokonalý. V určitých oblastiach však ponúka úplné nové, zmysluplné podnety, aby boli výpočtové jednotky čo najlepšie vyťažené. Okrem toho ponúka neskutočne vysoký texelfillrate výkon. Nad celou architektúra sa naozaj niekto zamýšľal.
Chladič je pre high end kartu prekvapivo tichý. Pri GTX verzii G80 sú potrebné dva 6 pinové konektory, pri GeForce 8800GTS len jeden 6 pinový konektor pre zásobovanie karty energiou.
Výhľad do budúcnosti:
Tak ako je G80 (NV50) dobrý, tak bude aj jeho nástupca – (NV55) vďaka niektorým interným vyplepšeniam – ešte výkonnejší. Či sa ďalšie zvýšenie výkonu dosiahne väčšou "šírkou" a vyššími frekvenciami alebo len frekvenciami nie je také podstatné. Väčší refresh (NV60) prinesie okrem zvýšenia výkonu aj zreteľné vylepšenia a rozšírenie feature set-u, pričom sa u (NV65) ešte viac zvýši výkon. Až potom pri (NV70) uvidíme kompletne novú architektúru. Neexistuje konečný čip.
Aj keď G80 vyzerá ako dobre – a technicky je veľmi dobrý – musíme ho brať len ako prvý čip jeho architektúry.
G80 ukazuje na všetkých frontoch, že sa nVidia poučila z minulých chýb. Vychytávanie chýba sa nezastavilo ani popri vývoji G80. Doteraz bol veľký výkonnostný náskok k predchodcovi u nVidie pri násobkoch dvadsiatky – NV20 (pri vysokej kvalite obrazu), NV40, nechajme sa prekvapiť NV60 ("G90"). Preto je aj prekvapivé, že sa nVidii podarilo so zavedením novej architektúry hneď dosiahnuť až taký veľký výkonnostný skok voči predchádzajúcej generácii.
Možno pomerne ľahko spozorovať, že sa nVidia zamýšľala nad tým, aby bola G80 architektúra rozšíritelná smerom hore. Čipy so 448 alebo 512 Bit zbernicou by nemali byť problém. Zo stránky features poskytuje G80 samozrejme všetko čo vyžaduje Direct3D10. Možno tiež predpokladať, že už teraz sa pracuje v Santa Clare na tom, aby bolo možné pri vydaní AMD/ATi R600 vydať, alebo aspoň ohlásiť rýchlejšiu GeForce 8 kartu.
Pokiaľ sa pozrieme do blízkej budúcnosti môžeme očakávať zaplavenie trhu rôznymi kartami postavenými na G80 architektúre. Vďaka skalárnosti a efektivite architektúry bude ešte viac platiť, "bang for the buck" ako by bolo možné dosiahnuť len zmenšovaním výrobného procesu.
Od ultra lowcost až k ultra high end kartám môže byť G80 architektúra využívaná, spolu s Direct3D10 feature set-om. Vynikajúci Direct3D 9 SM3.0 výkon je tak zaručený.
Pre G80 userov, je zatiaľ potrebné aby nVidia vylepšila hlavne ovládače. Control panel tieš nehodnotím ako veľkú novinku – tak by som privítal:
- používateľom nastaviteľný oversampling (supersampling) v 0.5 krokoch na x/y osy
- aby pri zapnutom AF bolo štandartne zapnuté trilineárne filtrovanie, nie brilineárne
- opravenie chýb, ktoré spôsobuje ovládač
glide
Ledy
barco
killswitch
crux2005
killswitch
crux2005
Ledy
killswitch
killswitch
crux2005
gogi
strelooriginal
dexman
eotslubo
optimista
badbat
MEPHISTO